Text-to-Speech (TTS) & Speech-to-Text (STT) Examples with Pawa AI
Text-to-Speech (TTS)
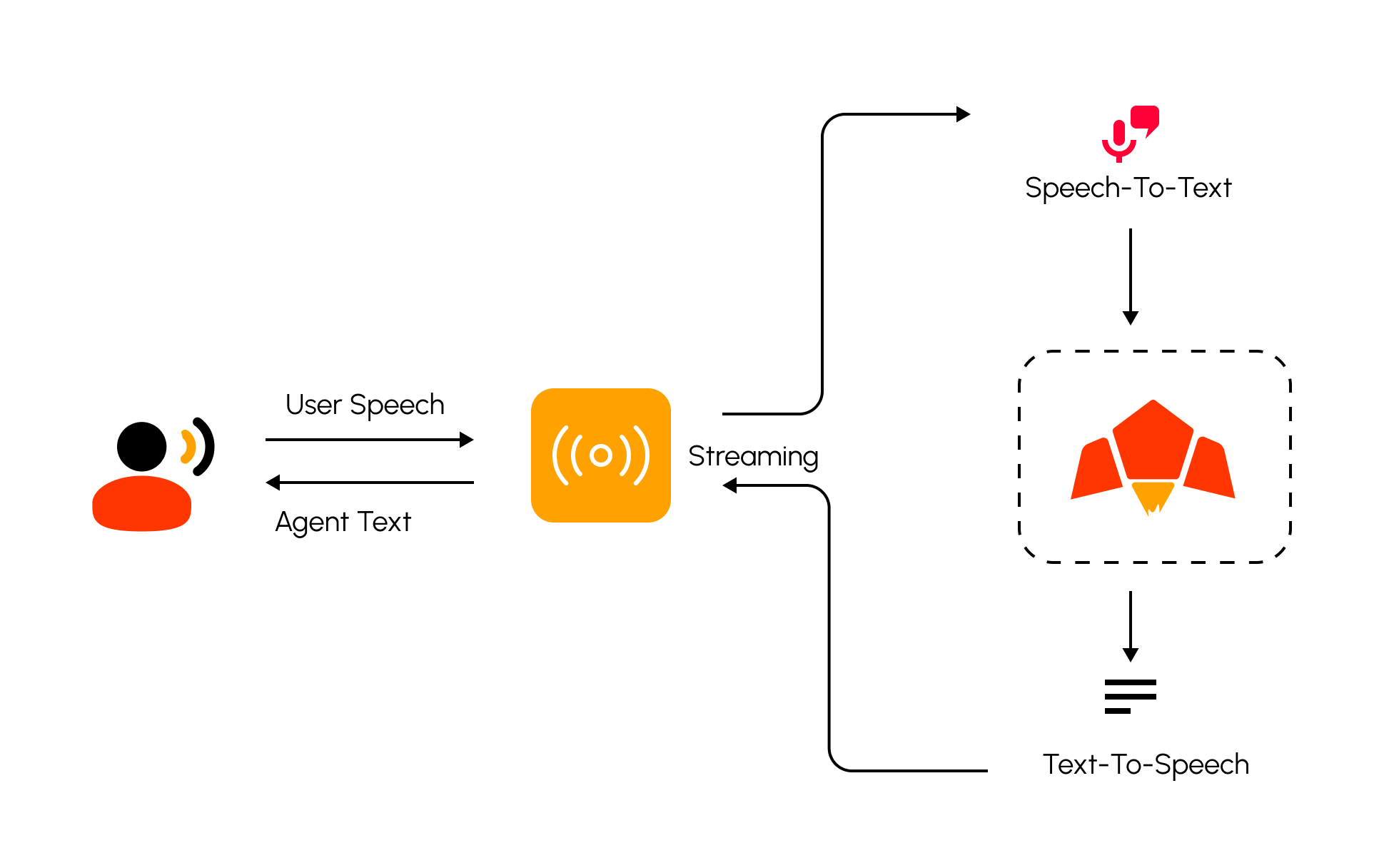
Text-to-Speech (TTS) allows you to generate high-quality, natural-sounding speech directly from text.This capability is essential for building voice-enabled applications, making content accessible to wider audiences, and creating immersive user experiences.
tts api endpoint implements streaming, so in your app you can directly use Server Side Event to get streaming of the audio back. If you dont use the SSE then the api will fallback to normal non sctreaming to wait for the full audio to be generated back give back answer.Supported Languages For Text to Speech
SwahiliEnglish
Use Cases
- Voice assistants: Let your chatbot respond with speech instead of text only.
- Learning platforms: Automatically generate audio versions of documents, lessons, or Q&A sessions.
- Accessibility tools: Help users with visual impairments interact with your app through audio.
- Media & podcasts: Generate narrations from written articles or blogs.
Voice options
The TTS endpoint provides 3 built‑in local voices to control how speech is rendered from text. This includesAmeLioraAyana
Models with Text to speech Audio Capabilities
- Pawa Text To Speech (
pawa-tts-v1-20250704) with text to speech conversation.
Original Text: “Jina la jamhuri ya muungano wa Tanzania, ni nchi iliyopo Afrika ya Mashariki ndani ya ukanda wa maziwa makuu ya Afrika, imepakana na Uganda na Kenya upande wa kaskazini, Bahari ya Hindi upande wa mashariki, Msumbiji malawi na Zambia upande wa kusini, Congo, Burundi na Rwanda upande wa magharibi, eneo la Tanzania ni takribani kilometa za mraba 940 mb/h. Saa arobaini na dakika elfu 300, eneo linalokaliwa na maji ne asalimia 6.2 - Mlima Kilimanjaro - Mlima mrefu zaidi barani Afrika upo kaskazini mashariki wa Tanzania.”
Text to Speech Request Example
Speech-to-Text (STT)
Speech-to-Text (STT) converts audio into text with high accuracy. With optionalspeaker identity, timestamps.This is powerful for transcription, audio search, summarization, and voice-enabled interfaces.
Supported Languages For Text to Speech
SwahiliEnglishLuoMerukambaHausaIgboYorubaZuluTswanaNyakoleetc…
Use Cases
- Meeting & call centers transcription: Turn long discussions into structured notes.
- Customer service: Convert call center conversations into searchable text.
- Education: Transcribe lectures, podcasts, and webinars.
- Productivity: Voice notes and dictation apps.
Models with Speech to Text Audio Capabilities
- Pawa Speech To Text (
pawa-stt-v1-20240701) with audio input to text conversation.
Example Text: “Jina la jamhuri ya muungano wa Tanzania, ni nchi iliyopo Afrika ya Mashariki ndani ya ukanda wa maziwa makuu ya Afrika, imepakana na Uganda na Kenya upande wa kaskazini, Bahari ya Hindi upande wa mashariki, Msumbiji malawi na Zambia upande wa kusini, Congo, Burundi na Rwanda upande wa magharibi, eneo la Tanzania ni takribani kilometa za mraba 940 mb/h. Saa arobaini na dakika elfu 300, eneo linalokaliwa na maji ne asalimia 6.2 - Mlima Kilimanjaro - Mlima mrefu zaidi barani Afrika upo kaskazini mashariki wa Tanzania.”
Speech to Text Request without Speaker Diarization Example
Example Response Without Speaker Diarization
is_speaker_diarization to true to enable speaker identity or diarization capability on the response
Example Response With Speaker Diarization
audio/mp3, audio/mpeg, audio/x-mp3, audio/wav, audio/wave, audio/x-wav, audio/x-pn-wav, audio/aac, audio/m4a, audio/x-m4a, audio/x-mp4, audio/ogg, audio/opus, audio/x-ms-wma, audio/wma with each of less 500MB. The server runs in batch mode of 5 files default.