Semantic Retrieval Example
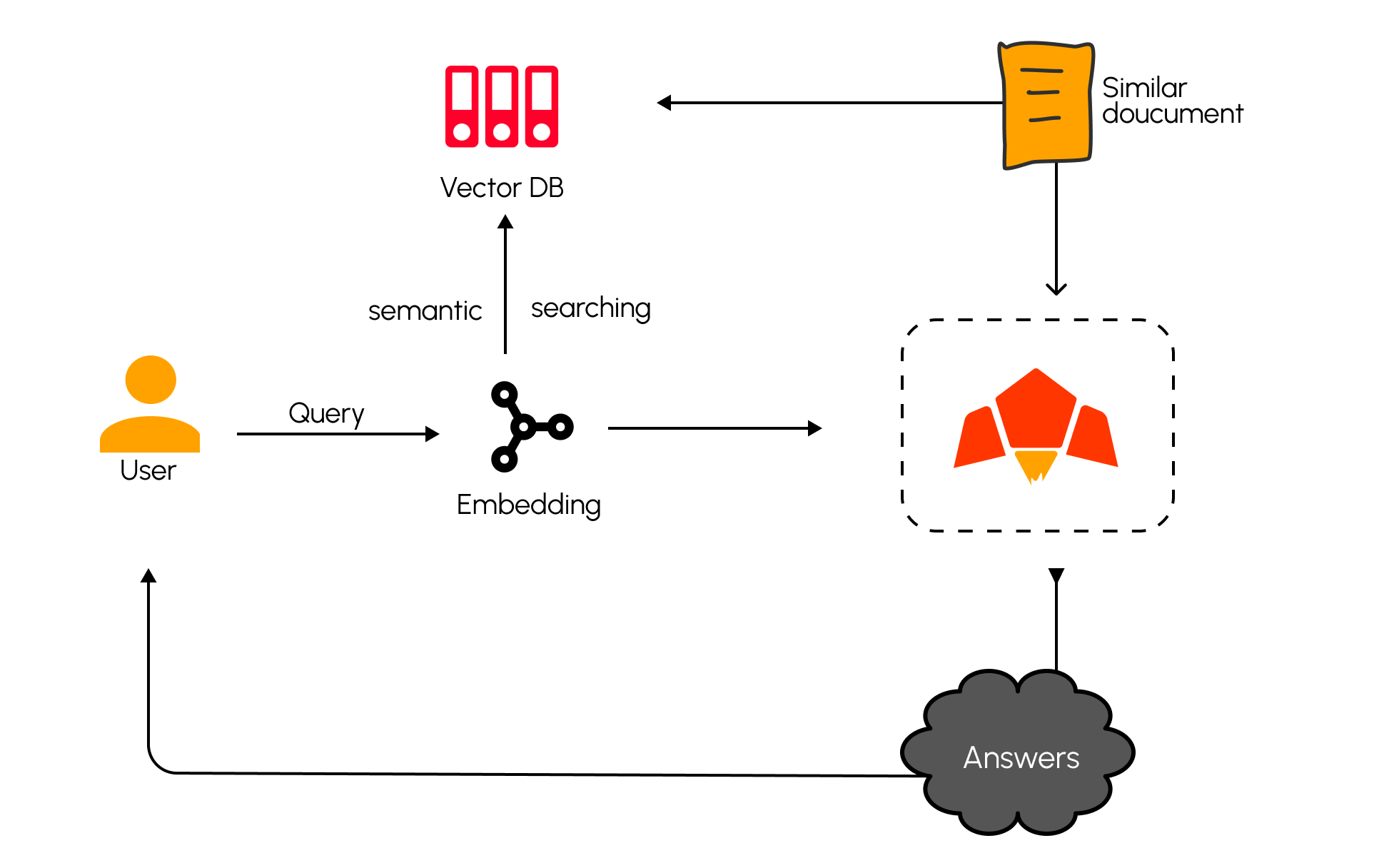
How it works
- Index your documents into Pawa AI’s knowledge base
- Query with natural language - ask questions in plain English or Swahili
- Get ranked results - most relevant documents appear first based on semantic similarity
- Use in RAG or elsewhere - feed retrieved context to chat models for grounded answers
This is the FREE endpoint, not cost associated with it. After creating knowledge base with Pawa AI , you can use the retrieval endpoint to get the top-k relevant results, that can be used in your RAG or else use cases.
What you can build
- Intelligent search across documents, PDFs, and knowledge bases
- Question answering systems that find relevant context
- Content recommendations based on semantic similarity
- Document discovery for large repositories
- Customer support with instant access to relevant help articles
Using Pawa AI Knowledge Base
Pawa AI provides a managed knowledge base with built-in semantic retrieval. Upload your documents and query them naturally. To learn more knowledge base in Pawa AI, see here.1. Create a Knowledge Base & Upload documents
2. Semantic Search across your knowledge
Response Format Example
Integration retrieval with Chat Setup
Combine semantic retrieval with chat models for powerful RAG applications:Best Practices
- Use descriptive queries: “What are the steps to file a complaint?” vs “complaint”
- Optimize chunk size: 500-1000 characters work well for most documents
- Filter by metadata: Use file types, dates, or categories to narrow results
- Combine with keywords: Use both semantic and keyword search for comprehensive results
- Monitor relevance scores: Adjust top_k based on score thresholds
Multi-language Support
Query in English or Swahili - Pawa AI understands both:Troubleshooting
- Low relevance scores: Try rephrasing queries or checking document quality
- Missing results: Ensure documents are properly indexed and not corrupted
- Slow responses: Reduce top_k or optimize document chunk sizes
- Language mismatch: Query in the same language as your documents for best results
Limits
- Maximum query length: 1000 characters
- Maximum documents per knowledge base: depends on your plan
- Response time: typically under 2 seconds for most queries