Pydantic or Zod to enforce data types, constraints, and structure.
Structured Output Example
Use Cases of Structured Output
📄 Document Parsing
Extract and organize content from PDFs, Word files, and other unstructured documents into usable data.
🔎 Entity Extraction
Identify and capture names, dates, amounts, and other key entities from raw text with precision.
📊 Report Generation
Automatically generate structured reports from language model outputs for analytics and insights.
📝 Resume Creation
Transform plain text into professional resumes or structured job application documents.
For JSON mode, it is essential to explicitly instruct the model in your prompt to output JSON and specify the desired format.Custom structured outputs are more reliable and are recommended whenever possible. However, it is still advisable to iterate on your prompts.
Use JSON mode when more flexibility in the output is required while maintaining a JSON structure, and customize it if you want to enforce a clearer format to improve reliability.
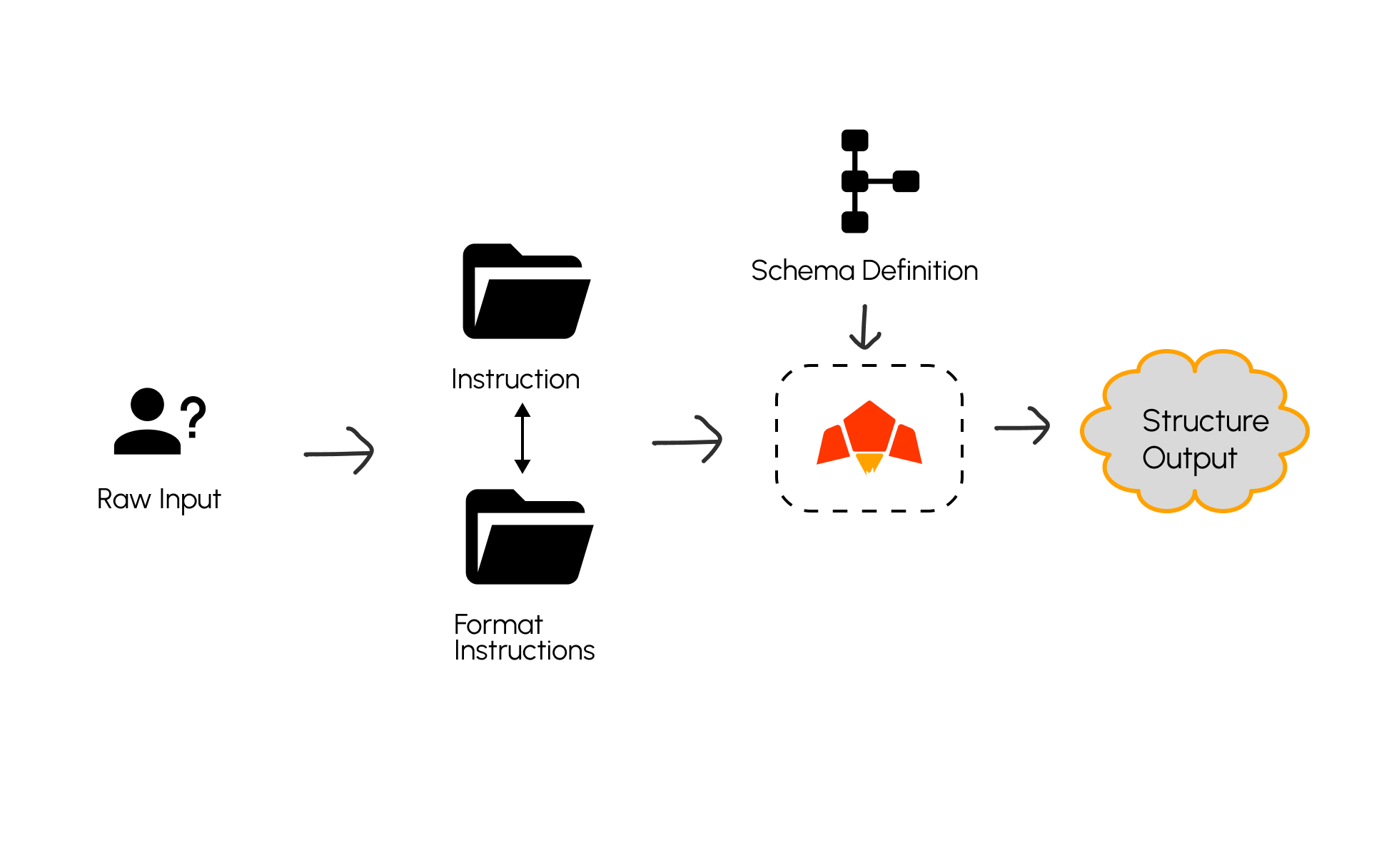
Why Use Structured Output?
- Ensure consistent responses
- Prevent parsing errors from free-form text
- Enable integrations with APIs, databases, or other systems
- Make automation workflows more reliable
Sending Structured Output Request in Pawa AI.
Sending request in Pawa AI you simply state your desired output format, for now the default is in JSON mode. You request the model to return the request in the specific JSON format you described in response_format parameter.
JSON Output
You can specify aresponse_format when calling the model to enforce a JSON schema.
Supported Schemas
For structured output, the following schema types are supported:- string
- number
- integer
- float
- object
- array
- boolean
- enum
- anyOf
Example: Resume Information Extraction with Structured Outputs
A common use case for Structured Outputs is parsing resumes. Resumes contain structured data such as a candidate’s name, contact details, education, and work history — but extracting this data from raw text can be error-prone. Structured Outputs ensure that the extracted data always matches a predefined schema.Step 1: Defining the Schema
Step 2: System Prompt
The system prompt instructs the model to extract structured resume data.Step 3: Example API Request to Pawa AI
Step 4: Example Type-Safe Output
This shows how Pawa AI can enforce schemas to reliably extract structured resume data.