RAG (Retrieval-Augmented Generation)
Retrieval-Augmented Generation, or RAG, is a technique that combines the power of language models with your own data sources. This approach ensures that AI responses are both relevant and accurate, even when the model has not been trained on your specific data.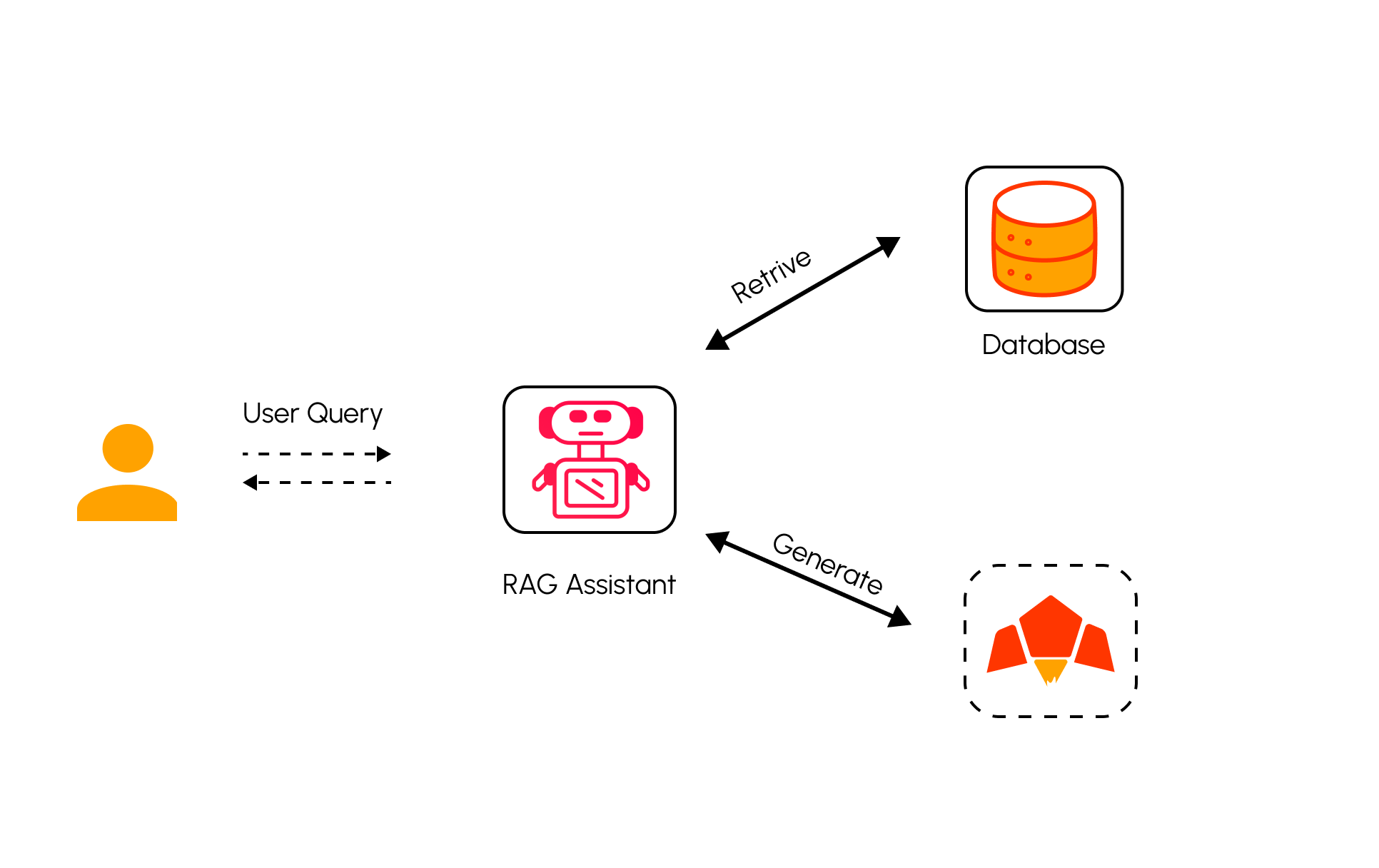
Build a RAG powered Apps, with Pawa AI
Register to Pawa AI, create a knowledge by uploading documents of your favorite, copy the kb-reference-id and send RAG requests.
Why RAG is Needed
Language models are typically trained on large amounts of publicly available internet data. While powerful, this training has two main limitations:-
Hallucinations (false answers):
Models may generate responses that sound correct but are factually inaccurate, especially when asked about data outside their training set. -
Missing internal or private knowledge:
Your business or organization may rely on proprietary or domain-specific data that is not included in public training datasets.
Examples:- Internal company policies
- Proprietary research papers
- Product manuals
- Customer support knowledge base
How RAG Solves This Problem
RAG reduces hallucinations and improves accuracy by retrieving relevant, trusted information from your data sources at the time of the request, and then passing that context along with the query to the model. This means:- The model has the latest, most relevant information available.
- Responses are grounded in your data instead of relying solely on general training.
- You can maintain accuracy and trust in critical use cases.
RAG enables you to enhance the model with your own knowledge base, ensuring that it can answer domain-specific questions correctly and reliably. With Pawa AI APIs, you can implement RAG systems easily, without dealing with unnecessary complexity.
Implementing RAG With Pawa AI in Your System
To implement RAG, you first need a Knowledge Base (KB) — think of it as your private reference library for the Pawa model. Traditionally, creating a KB involves setting up complex pipelines for extraction, chunking, embeddings, and retrieval. Each step needs to be efficient; otherwise, you risk retrieving irrelevant sources and producing incorrect answers. With Pawa AI, we’ve simplified this process. Our platform automatically handles extraction, chunking, and embedding using our models. Once complete, you’ll receive a Knowledge Base Reference ID, which you can pass as a parameter during chat requests. The Pawa chat API then incorporates your private reference source using semantic retrieval, ensuring that the model answers accurately based on your custom data.Step 1: Create a Pawa AI Account
- Sign up for a Pawa AI account.
- Verify your email and log in as a Builder.
Step 2: Create a Knowledge Base
- Navigate to the Storage page in your Builder Dashboard.
- Click Create Vector Store under the Vectors section.
- Upload files in supported formats:
.pdf,.docx,.txt,.mp3,.wav,.pptx,.xlsx,.png,.jpg, or provide URLs to your websites or online data. - Copy the generated Knowledge Base Reference ID. Eg.
kb-930d251e-8a8b-4ba9-bae1-5fceb47bd654
Step 3: Make Your RAG-Based API Request
- Use the Knowledge Base Reference ID in your chat API request.
- The model will retrieve relevant information from your KB to generate grounded, context-aware responses.
Example Response demonstrating RAG based chat
So, with this capability you don’t have to worry about building complex retrieval pipelines or managing embeddings yourself. Pawa AI handles the heavy lifting, letting you focus on integrating your data and delivering accurate, context-aware responses to your users.