Embeddings Example
What you can build
- Semantic search and retrieval‑augmented generation (where results are ranked by relevance to a query string)
- Recommendations (where items with related text strings are recommended)
- Deduplication and near‑duplicate detection
- Document classification and intent matching
- Classification (where text strings are classified by their most similar label)
- Clustering (where text strings are grouped by similarity)
- Anomaly detection (where outliers with little relatedness are identified)
- Semantic code or knowledge base search
- Diversity measurement (where similarity distributions are analyzed)
Embeddings Based Models in Pawa AI.
Currently we have one vision model:- pawa-embeddings-v1-20241001: High-quality vector representations for semantic search, clustering, and personalization.
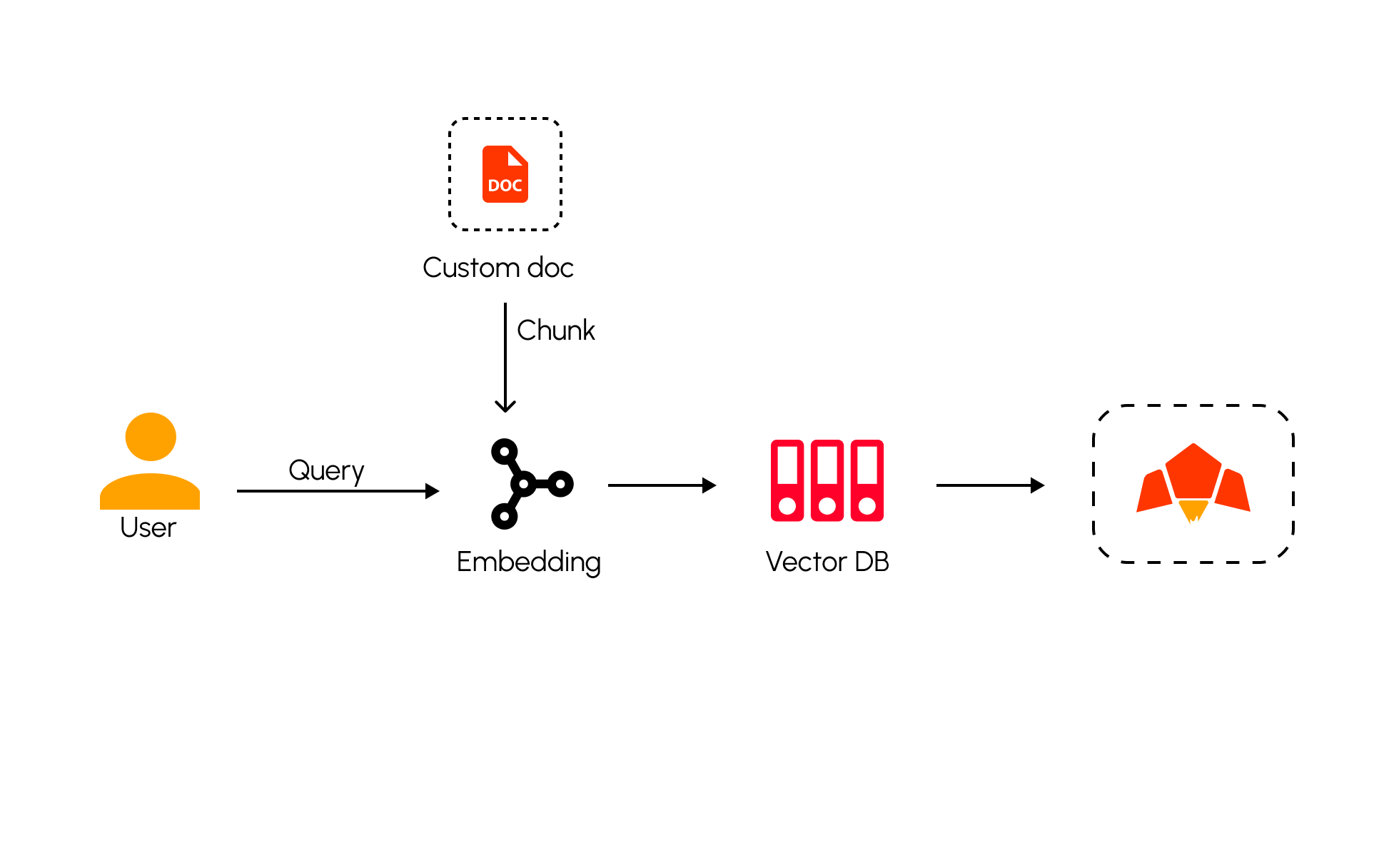
Create embeddings with Pawa AI
To get an embedding, send your text string to the embeddings API endpoint along with the embedding model name:The example of embedding response
The response contains the embedding vector (list of floating point numbers) along with some additional metadata. You can extract the embedding vector, save it in a vector database, and use for many different use cases.By default, the
pawa-embeddings-v1-20241001 gives the length of the embedding vector which is 4066.Best practices
- Chunk long documents (1024–2500 chars) with small overlaps (25-100)
- Normalize text consistently at index and query time
- Store embeddings in a vector database (pgvector, Milvus, Pinecone) with cosine similarity